The other day, a colleague stopped by my office to chat. We talked of the kids, our health, upcoming business travel, etc. The conversation eventually turned toward arcane points of IEC 61511 SIS engineering, as an alarming number of my conversations do. I expressed my controversial opinion in a haphazard way that I think impressed neither of us. This post is all the smart stuff I wish I had said in that conversation.
Background
A well-known report by the UK HSE “Out of Control: Why control systems go wrong and how to prevent failure” presents data that suggests that well over 50% of control systems failures are the result of error in the specification or design phases, as shown in the Figure below. Clearly systematic failures are a problem.
In the more recent SINTEF report “Common Cause Failures in Safety Instrumented Systems”, they note that “a potential CCF very much resembles a systematic failure”. Further, their analysis recommends Beta factors of 11-20% for many common safety devices, well beyond the range of 1-10% given in IEC 61508-6 Appendix D. Systematic errors may be a bigger problem than we thought! [Side note: these SINTEF results should be an alarm siren to the SIS world]
The data above is consistent with the philosophy of IEC 61511, which places great emphasis on the control of so-called systematic failures. However, the topic of systematic failures is a source of confusion in the functional safety community, in part because of the universally vague, frequently conflicting, and occasionally wrong guidance given in the standard. In this post, we will provide an overview of the topic, show how the standards may mislead users, and suggest an approach to how systematic failures should be treated.
What are Systematic Failures?
IEC 61511 2nd edition defines systematic failure as a:
“failure related to a pre-existing fault, which consistently occurs under particular conditions, and which can only be eliminated by removing the fault by a modification of the design, manufacturing process, operating procedures, documentation or other relevant factors”
The IEC 61511 definition differs slightly, but critically, from the IEC 61508-4 definition:
“failure, related in a deterministic way to a certain cause, which can only be eliminated by a modification of the design or of the manufacturing process, operational procedures, documentation or other relevant factors”
The IEC 61508 definition is better because it is more specific and much more limiting. According to this restrictive definition, systematic failures cannot be effectively modeled statistically because they are deterministic (i.e. non-random). Unfortunately, IEC 61511 expands the definition of systematic failures to include many non-deterministic failures, but then proceeds to advise that these failures should also not be modeled in SIL calculations.
Elsewhere in IEC 61511 (in a note on the definition for random failure) another useful comment about systematic failures is provided:
“a systematic failure can be eliminated after being detected while random hardware failures cannot.”
In my opinion, this is the best and most useful definition of systematic failure, but it is not the official definition! In other words, a systematic failure is something you can do something about, but even that leaves a lot of gray area.
The Trouble with the IEC 61511 Definition
IEC 61511 removes the word deterministic and replaces it with the far more vague words “pre-existing” and “consistently”.
Why is this a problem? Some systematic faults fault may not be “pre-existing”. For example, human errors are often systematic failures, but they are not pre-existing faults. Also, many systematic failures are still somewhat random in occurrence and do not “consistently occur”. For example, an error in the design temperature specification for a device may cause it to fail more frequently, but not predictably. The failure mechanism is may be systematic, but the failure frequency is still stochastic.
The table below shows a short list of systematic design errors and shows that the systematic SIF failures may manifest in either random or deterministic ways:
| Failure Description | Random? |
| Undersized Actuator will not Close Under Pressure | Deterministic (will never close) |
| Inadequate Freeze Protection | Random |
| Transmitter Design Temperature Underspecified | Random |
| Undersized Impulse Lines Plugged | Random |
| Process Safety Time Overestimated | Deterministic (never closes in time) |
| Fail to Anticipate High Vibration | Random |
| Manufacturer Component Quality Issues | Random |
The majority of systematic issues result in higher failure rates, not just deterministic failures and not always 100% reproducible. Under a strict interpretation of the IEC 61508 definition, these would not even be considered systematic failures!
Conflict of Interest?
The conflicting messages in the standard are unfortunately often reinforced by vendors and SIL certifying bodies. Worried about plugging, fouling, corrosion, leakage, freezing, wear, vibration, lightning, misconfiguration, operator error? Sorry, those are systematic failures and are not included in your SIL-certificate failure rate! The result is that failure rates from SIL certificates are frequently an order of magnitude lower than field data from end users (e.g. OREDA, PERD, NUREG). Just because vendors ignore systematic failures doesn’t mean end users should!
Schizophrenic Standard
These quibbles about definitions would not be such a big deal, except that after vastly expanding the world of possible systematic failures, IEC 61511 then proceeds to give conflicting guidance on what to do about systematic failures.
Regarding measurement of systematic failures, on the one hand it says:
“hardware failures can be estimated from field feedback while it is very difficult to do the same for systematic failures.”
Then later in the document it implies the opposite:
“the main intent of the prior use evaluation is to gather evidence that the dangerous systematic faults have been reduced to a sufficiently low level”
I believe the second quote is correct. Clearly, a systematic failure is still a failure, and failures can be monitored based on field feedback. This is why prior use data is preferred over hypothetical FMEDA or lab test data.
Elsewhere in the standard, it asserts that systematic failures cannot be modeled quantitatively:
“safety integrity also depends on many systematic factors, which cannot be accurately quantified and are often considered qualitatively throughout the life-cycle”
Yet the standard also requires in multiple places that common cause be considered in the design and included in the SIL calculations, and this is common practice. Common cause failures are dominated by systematic failures, yet we have no problem modeling them quantitatively…? For another example, the entire field of Human Reliability Analysis (HRA) is dedicated to quantitatively modeling the largely systematic failures of human beings.
In fact, the ISA Technical Report on SIL Evaluation Techniques (ISA TR-84.00.02-2002 – Part 2) published 16 years ago specifically covers methods to quantify systematic failure probability in SIL calculations. It seems to me that over the intervening years, the idea that systematic failures are “difficult to quantify” has slowly morphed into “don’t need to be quantified”. I believe this is a mistake and leads to nothing but confusion in the SIS field.
Clearly, systematic failures can be quantitatively modeled. The key distinction is that they should not only be modeled. Recall that once detected, systematic failures can often be eliminated. The difficulty comes in classifying failure types as random or systematic. But does classification really matter?
A Distinction Without a Difference?
The classification of a failure as random or systematic is difficult because it is largely a subjective exercise. For example, what if a device rated for 150 degF is installed in a location that is normally ~100 degF, but one day it gets up to 145 degF and the device fails. Is this a random failure since the temperature was less than the design temperature? Or was it a systematic failure because the specification failed to include adequate safety margin to account for variations in temperature? A case could be made either way. But who cares? Is there a difference, really?
Classifying things as systematic failures really just acknowledges that there are failure mechanisms that do not fall neatly into the physics models and accelerated test plans used to predict failure rates. In addition to the aleatory uncertainty that exists even in relatively ideal conditions, there will always exist additional epistemic uncertainty due to things like human error, application condition changes, supplier quality issues, etc. The end result is simply that uncertainty is higher than we might expect in the idealized model. This can be visually demonstrated in the traditional stress-strength model of reliability:
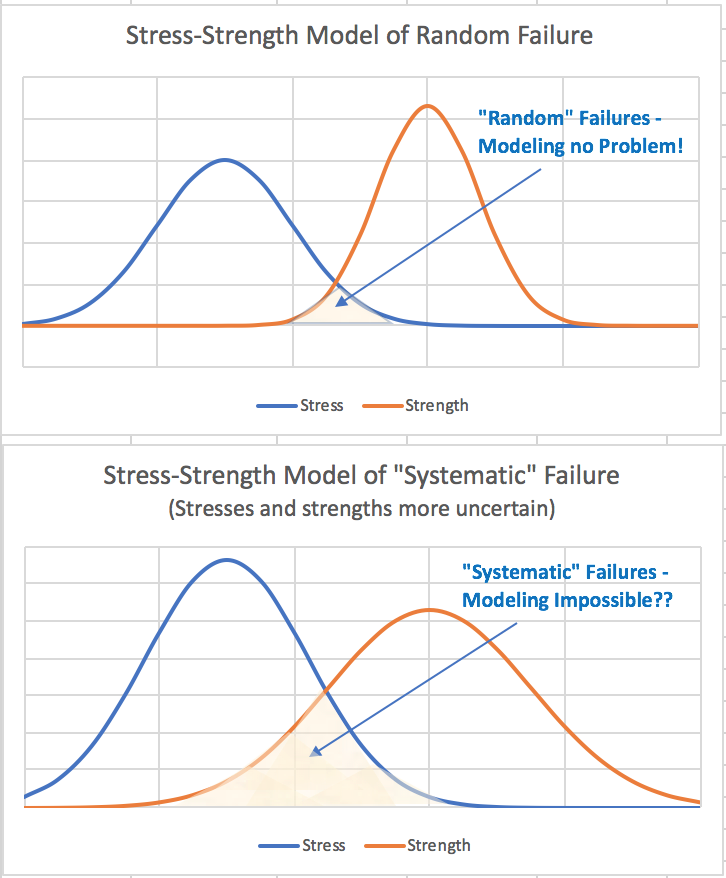
Why is one form of uncertainty required to be quantitatively modeled, but the other is dismissed as “difficult” and need only be considered qualitatively? It seems to me an unnecessary and unfortunate distinction. A SIL calculation based on end-user failure rate data containing both random and systematic failures will more accurately represent the probability of failure on demand. Isn’t that the point of the calculation?
At the fundamental level, every failure is a potential systematic failure. As per the IEC 61511 definition above, the important question is now that you know about it, can it feasibly be eliminated? Now this becomes a question not of philosophical classification, but just practical questions of (i) whether the fault can feasibly be eliminated and (ii) what safeguards can be put in place to prevent the same problem from occurring elsewhere.
A Bayesian Side Note
I think part of the reason the standards distinguish between random and systematic failures is that they are influenced by Frequentist statistical thinking, which often separates aleatory uncertainty (i.e. randomness) from epistemic uncertainty (i.e. state of knowledge). Epistemic uncertainty does not fit well into the frequentist philosophy, so they try to avoid or eliminate it. A funny example I heard somewhere:
Question: What is the probability that an asteroid will destroy the earth tomorrow?
Frequentist Answer: The probability is either 1 or 0. I will let you know day after tomorrow.
On the other hand, Bayesians treat epistemic uncertainty the same way as aleatory uncertainty. A Bayesian probability represents a “degree of belief” or a “state of knowledge” and can incorporate all forms of uncertainty.
For frequentists, epistemic uncertainty must be qualitatively avoided or minimized. For Bayesians it can be treated as part of the quantitative model. SIS engineers are inherently Bayesian (see my Bayesian paper) and should embrace this philosophy
Conclusions
This post has been longer and more philosophical that many of my posts, so let me try to sum it up succinctly. My key points are:
- IEC 61511 expands the definition of systematic failures beyond IEC 61508 and leads people to think that many common SIS failures are systematic and therefore need not be quantitatively modeled. This is an error since the PFDavg calculation should incorporate all available available information to make it an accurate and useful metric.
- Many systematic failures are stochastic in nature and can (and should) be probabilistically modeled. Rough estimates of systematic failure rates can be found by comparing end-user data to theoretical data. These estimates can be refined per application based on user data.
- The distinction between systematic failures and random failures is not as important as people make it seem. Every failure should be considered a potential systematic failure until it is determined to be infeasible to address it.
Do you agree? My colleague was intrigued but not convinced. Maybe this post will help. Hopefully this post doesn’t discourage colleagues from chatting with me in the future! 😉
Please post your questions or comments and don’t forget to follow us on LinkedIn. Thank you! Please checkout other popular FunctionalSafetyEngineer.com posts, including:
I would be interested in learning who wrote this article.
Hi George, all of the content on the site is currently by me, Stephen Thomas (https://www.linkedin.com/in/stephenlthomas/). Thanks for reading!
Very interesting article and good read. Also very interesting SINTEF Report, yikes! I just stumbled upon your site from looking at your profile on LinkedIn. I co-wrote and presented a paper with a college at the TAMU Symposium last month very much in line with this article “Can we achieve Safety Integrity Level 3 (SIL 3) without analyzing Human Factors?.” It’s up on our company website (sorry I can’t post a direct link it seems – https://www.aesolns.com/news-resources/white-papers/). This article gives me some ideas for a follow up paper. Will be checking out more of your site!
I love this, Stephen. It’s been a topic that has brought me so much confusion.